Vývojáři používají mikroslužby jako vzor škálování architektury aplikací. Musí také poskytovat přístup ke svým systémům prostřednictvím různých rozhraní - desktopových, mobilních webových, mobilních aplikací a různých třetích stran prostřednictvím rozhraní API. Navrhnout vhodnou přístupovou architekturu je náročné, zejména když máte také některé starší systémy a služby, se kterými musíte komunikovat. Podívejme se na jeden návrhový vzor, který může pomoci.
Monolit, ale pro rozhraní
Čerpám ze zkušeností, které vidím při svých příležitostných konzultacích, zejména v maloobchodních a e-commerce organizacích, ale předpokládám, že je to všude stejné. Když tyto společnosti řeší vícekanálové strategie, uvědomují si, že budou potřebovat množství rozhraní pro zákazníky s jejich specifickými potřebami, ale všechna musí čerpat ze stejných dat. To logicky vede k návrhu systémů orientovaných na služby. Obecnou myšlenkou může být například vybudování odděleného katalogu produktů, který bude poskytovat informace o produktech všem ostatním systémům.
Takový komplexní katalog produktů lze vybudovat jako samostatnou službu. Všechna uživatelská rozhraní a externí systémy se pak převedou na používání této služby s jejím společným API. Viděl jsem také starší systémy převedené na takovou službu přidáním API, které vystaví některé objekty a metody z monolitického systému. To vlastně není špatná strategie pro přechod na plně servisně orientovanou architekturu, ale je třeba zajistit, aby to tak nezůstalo navždy.
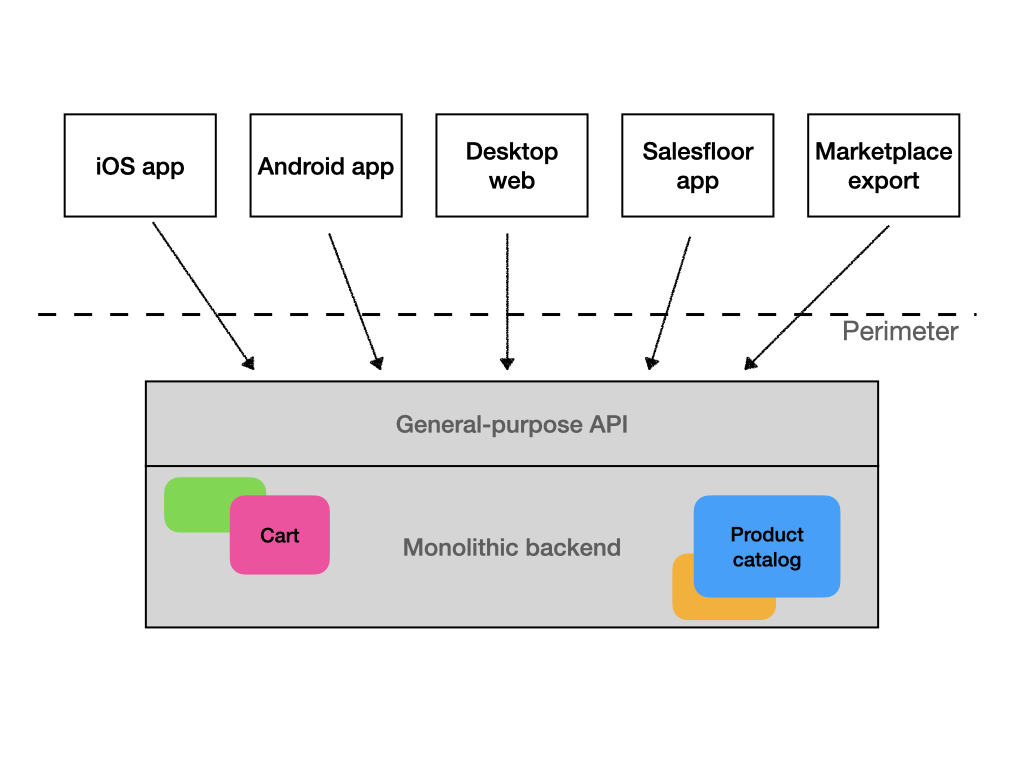
Tento přístup, který je na straně služeb relativně jednoduchý na implementaci, má své vlastní problémy. Protože rozhraní API používají všichni, musí poskytovat všechna data a všechny metody, které by kdokoli mohl kdy potřebovat. To znamená, že bude všechno, jen ne “mikro”, a co je důležitější, konzumenti tohoto API (myslete například na vývojáře frontendů) se budou muset naučit mnohem složitější rozhraní. Když k tomu přidáme potřebu komunikovat s klienty, kteří ovládají jiné serializační a volací mechanismy, například gRPC nebo SOAP, může se služba velmi rychle nafouknout. Konzument také obvykle dostane více dat, než je nezbytně nutné pro to, co chce dělat, jen proto, že by je mohl potřebovat někdo jiný, a vytváření speciálních koncových bodů pro každý typ konzumenta by bylo zdlouhavé a opět by zvětšilo velikost služby a rozhraní. Pokud je služba konzumována přes internet, a to zejména přes pomalý internet, jako je mobilní, přináší to také problémy s výkonem frontendu a vybíjí to baterie.
Tomu říkám monolitické rozhraní.
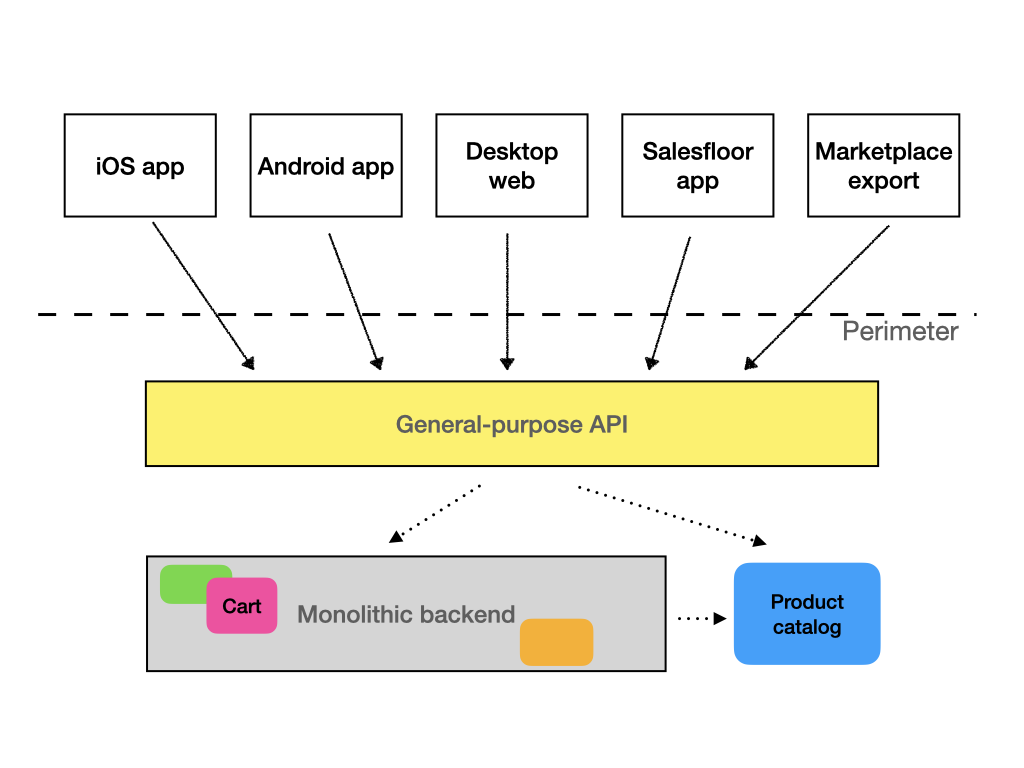
Segregace rozhraní
Pohled ze strany konzumenta je jiný. V ideálním případě by každý konzument měl dostat speciální rozhraní, které by vyhovovalo jeho potřebám a poskytovalo pouze data a metody, které potřebuje, a nic víc. Jeden konzument ani nepotřebuje vědět o ostatních verzích rozhraní API. To by bylo efektivní nejen proto, že by se snížila kognitivní zátěž vývojářů na straně konzumentů, ale také z výše uvedených výkonnostních důvodů.
Tomu říkáme segregace rozhraní.
Záchrana pomocí API brány?
Jednou z běžných funkcí většiny API bran (API gateway) je možnost upravovat zprávy během přenosu. Můžete některé věci odstranit, přejmenovat pole, dokonce převést službu gRPC na službu HTTP. Vypadá to tedy jako dobré místo pro dosažení segregace.
Určitě to lze udělat, ale nedoporučoval bych to, s výjimkou specifických případů. Brána má často jiný styl konfigurace než kód, který vystavuje. Hlavním problémem jsou však odpovědnosti. Nejčastěji bránu spravuje jiný tým než ten, který vytváří API, které vystavuje. Často ji spravuje spíše provozní než vývojový tým. Samoobslužné změny konfigurace jsou možné jen zřídka. To zavádí velmi těsné propojení mezi týmy, což není něco, co byste chtěli.
Využití API brány může mít smysl, pokud máte jen jeden tým, který může spravovat změny v celém ekosystému. To však není příliš časté, protože to také pravděpodobně znamená, že vaše potřeby jsou poměrně jednoduché a monolitický systém by byl správnou architektonickou volbou.
BFF
Pokud API brány a monolitická rozhraní obvykle nejsou vhodnou cestou, co tedy ano? Odpovědí je vyhrazené rozhraní Backed-for-frontend neboli BFF. Pro každou třídu klientů nebo dokonce pro každého jednotlivého klienta vytvoříme samostatnou službu API, která prezentuje data způsobem, který je pro konzumenta výhodný, a obsahuje pouze metody, které konzument používá. Může být mnohem štíhlejší než univerzální API a rychleji se měnit.
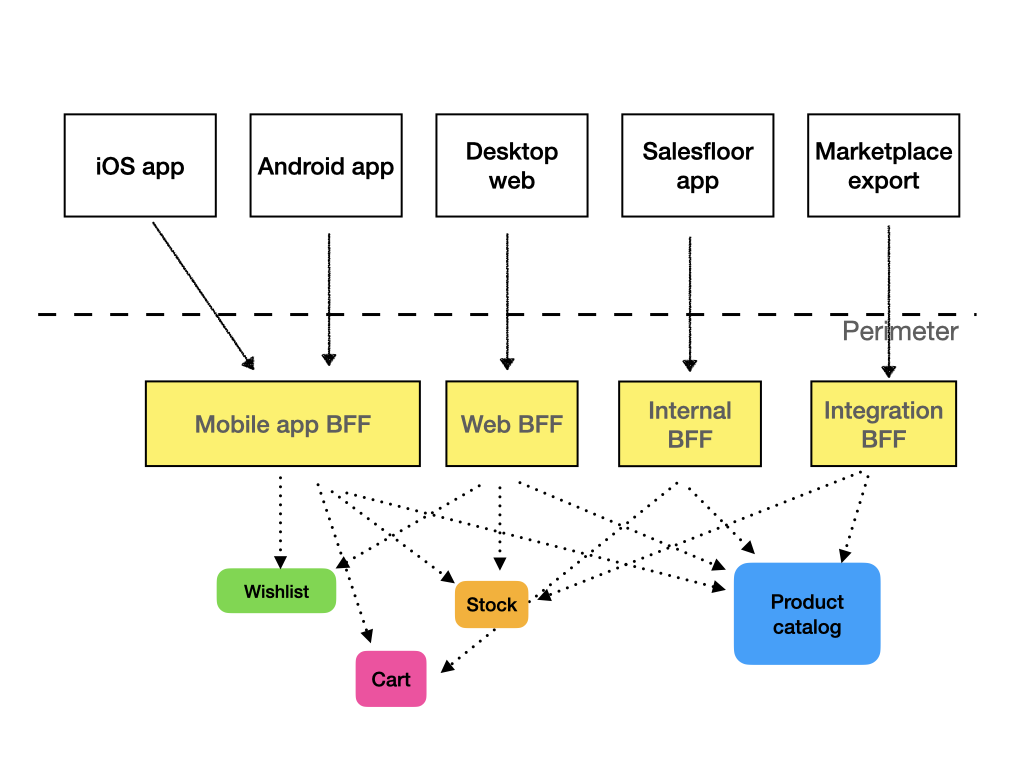
Z organizačního hlediska má smysl umístit tyto BFF co nejblíže konzumentům. Například váš webový frontendový tým může spravovat BFF pro webové API. Pokud máte tým mobilních vývojářů, mohou spravovat rozhraní API pro mobilní aplikace. Pokud máte oddělené vývojové týmy pro Android a iOS, může mít dokonce smysl, aby každý z nich měl samostatný BFF. Budete mít určitou duplicitu, ale mějte na paměti, že BFF by měly být velmi odlehčené, bez obchodní logiky.
Možná budete v pokušení abstrahovat společné funkce těchto BFF do sdílené knihovny. Mám na mysli věci jako sanitizace vstupu, logování, trasování. Zde však existuje velmi tenká hranice, kterou je snadné překročit a skončí to těsně spřaženým nepořádkem. Mám špatné zkušenosti s věcmi, jako je vytvoření společné knihovny pro HTTP klienta, která dělá spoustu věcí navíc. Tyto sdílené knihovny mají tendenci se nafouknout, protože si tam každý přidává své věci a může to vytvořit velmi těsné, ale většinou neviditelné propojení mezi službami. Nasazení nové verze jedné služby najednou znamená, že se nějaká jiná služba rozbije (když nejsou dostatečně striktně ošetřeny závislosti) nebo potřebuje nechtěný refaktoring. Záležitosti jako logování a autentikace je také obvykle lepší řešit buď na perimetru (inteligentní proxy), nebo prostřednictvím service mesh.
Sam Newman popisuje vzor architektury BFF ve svém podrobném článku, takže doporučuji, abyste se na něj šli podívat.
Skládání služeb
Jednou z rolí, které může BFF plnit, je skládání volání služeb. Řekněme, že máte službu nákupního košíku a službu katalogu produktů. Když zobrazíte obsah uživatelova nákupního košíku, zavoláte nejprve službu košíku, abyste získali seznam ID produktů s množstvím. Poté musíte zavolat službu katalogu produktů, abyste získali podrobné údaje o produktech, například jejich názvy a obrázky.
Jedním ze způsobů, jak to provést, je frontend. Pokud však hovoříme o aplikacích dodávaných přes internet, je to spojeno s velkým zpožděním. Pokud je cesta od klienta k serveru 300 ms (což není v mobilních sítích nic neobvyklého), i při okamžité odezvě serveru se dostanete na dobu odezvy 600 ms, než získáte data potřebná k zobrazení stránky. A to ani nemluvím o tom, že po získání dat o produktu musíte požádat o obrázky a provést další roundtrip, abyste je obdrželi. Jistě, můžete použít nějaké efektní věci, jako jsou zástupné symboly a progresivní vylepšení, ale data o produktu jsou zatraceně důležitá, takže bez nich může být obrazovka z větší části nepoužitelná. Pokud vytváříte interní aplikaci, u které se předpokládá, že se bude konzumovat přes lokální síť se submilisekundovým roundtripem, je to pravděpodobně v pořádku. V opačném případě bude vaše aplikace poskytovat špatný uživatelský zážitek.
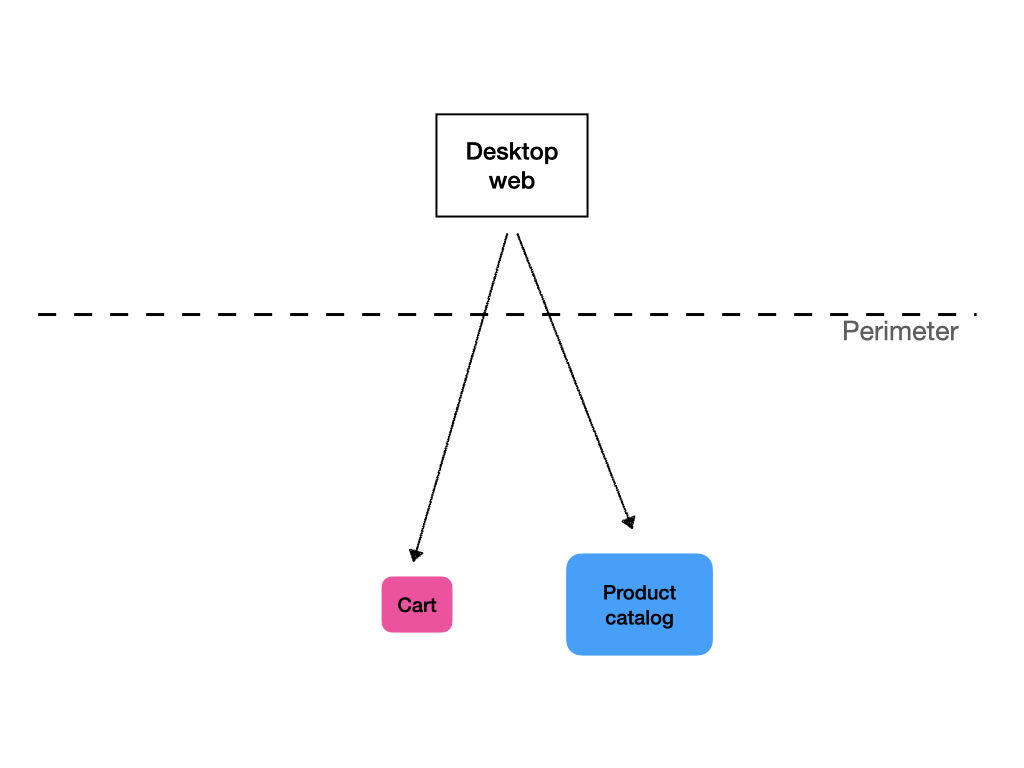
Pokud většina volání služby košíku vede k následným voláním služby produktu ze strany klienta, dává smysl, aby rozhraní API vracelo data košíku obohacená o data produktu. Tímto způsobem musí klient provést pouze jeden roundtrip.
Jedním ze způsobů, jak toho dosáhnout, je řetězení samotných služeb. V tomto scénáři by služba košíku zavolala službu produktu a vrácená data by použila k obohacení odpovědi.
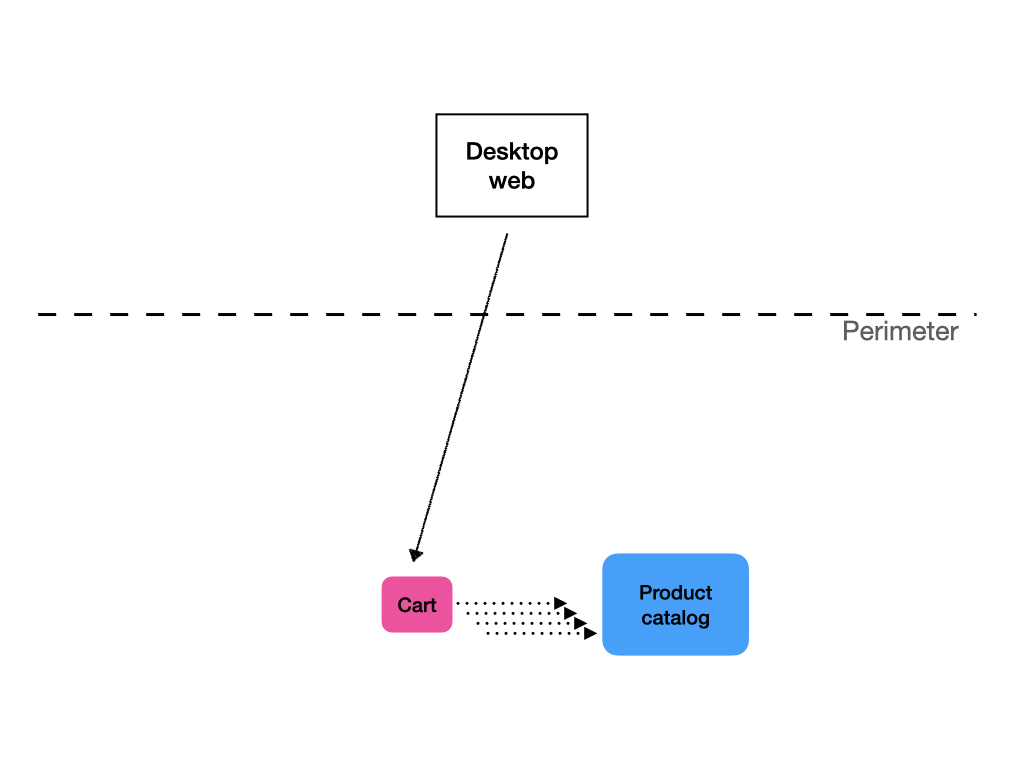
Druhý způsob je provést to v API službě. I v tomto případě mají oddělené BFF smysl, protože obecné API by pravděpodobně buď obohacovalo data mnohem více, než je nutné, což by mělo dopad na výkon, nebo by muselo klientovi poskytnout způsob, jak specifikovat, jaká data chce, což by zvýšilo složitost a ztížilo učení použití služby.
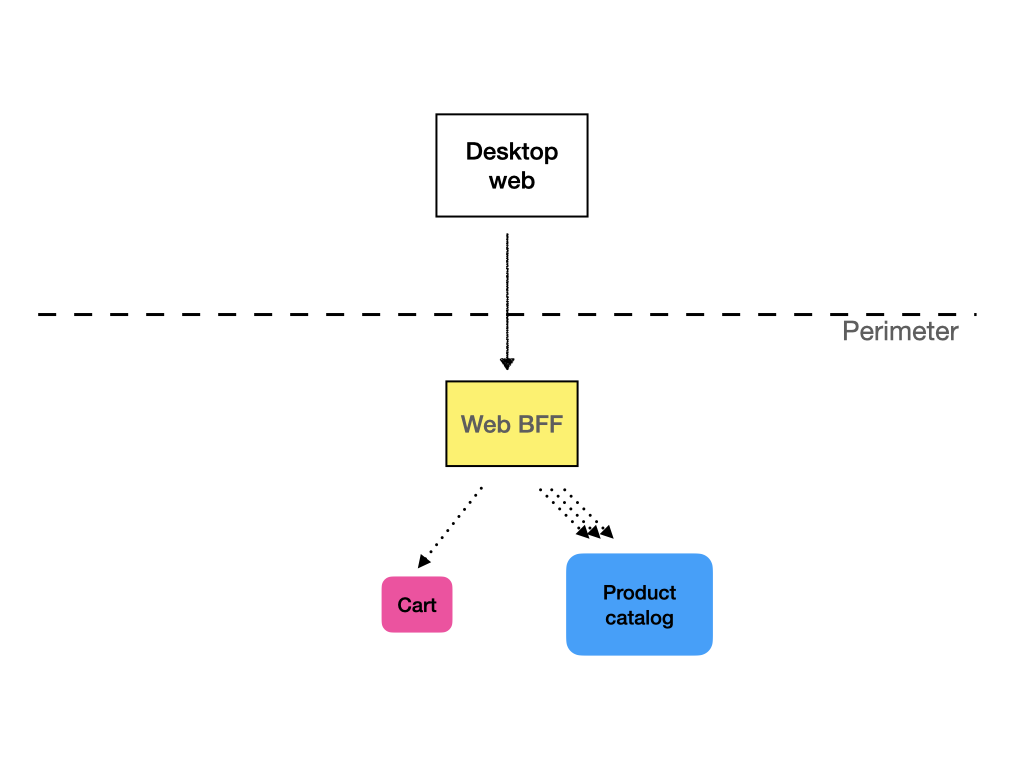
Překlenutí věkového rozdílu
Segregace rozhraní je také užitečným vzorem, pokud budujete nový ekosystém mikroslužeb, ale musíte jej integrovat se staršími systémy a službami. Řekněme, že začnete budovat moderní infrastrukturu propojenou service meshem, jako je Istio nebo Consul. Zároveň máte služby mimo tuto infrastrukturu, které stále potřebují komunikovat s těmi novými. Vytvoření BFF pro tyto nové služby může být dobrým způsobem, jak tyto dva světy propojit. Protože BFF by měl být určen pro konkrétního klienta nebo třídu klientů, můžete tato rozhraní API vyřadit, jakmile budou tyto starší služby přepsány do nové infrastruktury. Pokud byste udělali jedno obecné “legacy” API, mohu vám v podstatě zaručit, že ho budete udržovat navždy.
Závěr
Segregace rozhraní vychází z principů mikroslužeb a přizpůsobuje je návrhu API. Pomáhá vytvořit štíhlé efektivní rozhraní pro vaše služby a posouvá vývoj blíže ke konzumentům. Může pomoci zlepšit výkon služeb, zejména v mobilních sítích, a zároveň zachovat menší rozsah služeb. Stejně jako mikroslužby má smysl ve větších prostředích s více týmy, protože jim umožňuje větší nezávislost a rychlé změny.
Comments