When we talk about complex systems, one of the studied properties is often the resilience of the system. By resilience we mean the capacity to recover from difficulties or failures. It’s often talked about in the realm of computer systems, but applies as well for others systems such as organizations. It’s helpful to classify the level of resilience, so that we can assess the current state of our system and decide if we want to invest in increasing it’s resilience, based on how critical the system is.
Level 1: Fragile
In the lowest, or least resilient level, a system can be described as fragile. A fragile system does not tolerate any failures. If put under very little stress, it breaks.
Fragile systems are usually either result of existence of single points of failure (SPOFs) or insufficient capacity.
It’s obvious that if a component can cause system breakdown, the system is only as resilient as the least resilient component. The situation gets even worse when there are multiple such components, as a failure of any of them can cause system breakdown and the probabilities add up.
Less obvious is the case when system is operating close to it’s capacity in some form. Failures of this nature can happen in systems that are seemingly resilient in a way that they are built using redundant components, so they do not possess any SPOF.
One such example could be a cluster of web servers, each with a limited worker pool with a load balancers in front of them. Such system seems like it’s resilient without SPOFs. If the system is operating close to exhausting the worker pool on the web servers, it is however fragile. This fragility comes from the fact, that as soon as the traffic increases even a little, one of the web servers will exhaust it’s worker pool. This may increase the latency to a point where the load balancer will consider the server dead, take it out of the rotation, thus overloading the remaining servers and the whole system breaks down as all of the web server are considered dead. Such a system will usually not recover by itself, even if the traffic drops slightly, because the load balancers will almost never put all the web servers back into the rotation at the same time. It may require a human operator to realize such state has occurred and to manually reset the load balancer.
This system fragility is much harder to detect than SPOFs. It’s often the case that the system is operating smoothly up to a certain point but breaks down completely very quickly on even a 1% throughput increase. It’s also very easy to confuse the cause and the effect. Are the servers overloaded because the worker pool is exhausted, or is the worker pool exhausted because the servers are overloaded?

Level 2: Robust
If a system is able resist some failures or increased stress (up to a certain limit) we call it robust. It will not break down as easily as a fragile system, but it will break down at some point as well.
A robust system will not have any SPOFs, ensured by having redundant components and the ability to route around any individual component failure. The problems described in the fragile system example can be mitigated by using queues to protect any capacity constricted components. The queue will cause some requests to be delayed, but the system will still operate. The slowdown is also relatively easy to observe and monitor for and gives the system it’s robustness by resisting complete breakdown, even if the system is over capacity. Until the queues also fill up, the system is able to operate, albeit in degraded form.
Another successful technique for making robust systems is rate limiting. It means outright refusing to serve the work requests which would take system over it’s capacity. It’s always better to be able to serve 80% of your customers than not serve any at all, because the system exhausts it’s resources and breaks down completely, as was the case with the fragile system.
The redundancy also makes the system robust. As long as enough copies of a component are alive to handle the load, the system is able to operate. Maybe it will be slower and it’s capacity is reduced, but it will function.
Robust system is obviously much better than fragile system. It’s able to resist, but it’s still not able to adapt.

Level 3: Resilient
A resilient system is one that can adapt to failures or increased stress. Now we are getting somewhere, finally.
Not only can such a system be free from any SPOFs and must be able to withstand any bursts of activity thru queues and bulkheads, but it has to actively adapt and change itself. It’s possible for such a system to be changed by human operator, but mostly that is not the case, because it would require the operators to constantly monitor the system and be able to react quickly enough. So most probably, in order to achieve a resilient system, it must possess the ability to change itself automatically and that requires intelligent programmable platforms, such as public or private cloud infrastructures.
We’ll not go into too much detail here, but one example can be employment of autoscaling groups instead of fixed resource groups in your cloud platform of choice. The autoscaling group can automatically replace failed servers and can increase (or decrease) the number of servers based on current load or throughput. That way, the failure of a component will not decrease the overall capacity of the system and the increased traffic should not increase the system overall latency, as was the case in a system which was only robust.
Remember we do not just resist. We adapt. So unless you exhaust you credit card for cloud services, you should be fine. Or your database connections run out.

Level 4: Anti-fragile
Can there be something better than system being resilient, you ask? Well, apparently there is one more level up. Instead of the system being able to withstand failures, it can actually improve and get better. We call this anti-fragile.
It’s hard to find examples of computer systems which are anti-fragile, because it’s difficult to imagine a system which can provide a better service than originally designed. But there are many other system classes that we can observe. For example organizations are also systems.
It’s not too hard to imagine a company, which goes thru a crisis which makes it stronger if it’s anti-fragile in it’s nature. Or consider an amazing complex system called the human body. If you put it under constant stress by exercise or cold water therapy, it will improve itself and you will be able to achieve things previously unimaginable.
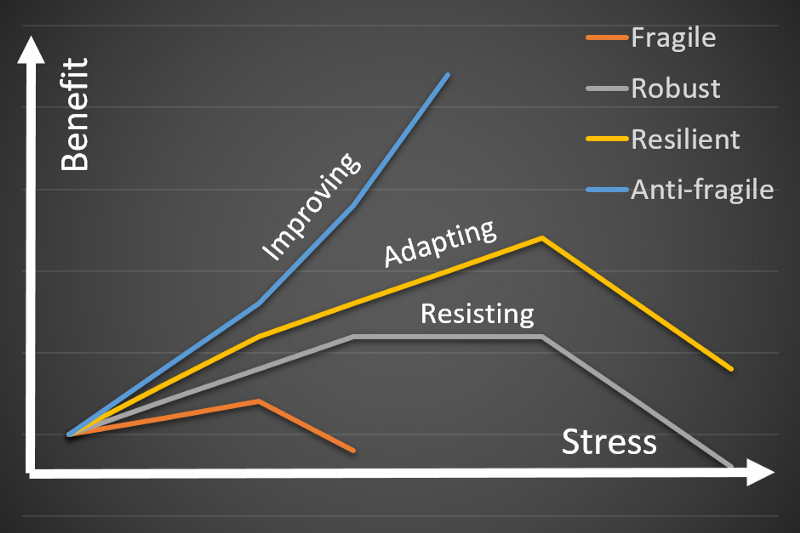
This four-level classification of system resilience can be helpful in your journey for better systems. It helps you assess in which phase your system is and also enables you to reason about where your system should be, because not all systems need to be resilient or even robust.
In future articles, I’d like to explore techniques for “leveling up”, so stay tuned.
Comments