Říkali jste, že vývoj toho úkolu zabere jeden den, ale už jsou to tři měsíce a pořád to není hotové!
Náš marketing si tu kampaňovou stránku raději spíchnul sám někde bokem, protože kdyby to dali na IT, nebylo by to hotové nikdy.
Něco vám to připomíná? Já byl na obou stranách této konverzace, ale mnohem častěji na té straně, na kterou se nadávalo. Dlouhou dobu mi to vrtalo hlavou. Proč jsme se do takové situace dostali?
Příprava scény
Máte celkem slušný vývojový tým. Rozhodně stojí víc peněz, než se vašemu finančnímu řediteli zamlouvá. I přesto se ale vývoj posunuje hlemýždím tempem, minimálně podle vašich uživatelů. Jasně, nějaké úkoly se vám daří dokončovat, ale řada dobrých nápadů, které by ani nezabraly tolik vývojového času, se zabije hned na začátku, protože nikdo nechce čekat do příštího kvartálu na ověření jednoduché obchodní hypotézy.
Řada firem s vidinou vyřešení tohoto problému zavede nějakou formu agilního řízení vývoje. Často to totálně selže. Co vám totiž ti certifikovaní Scrum konzultanti neřekli je, že Scrum optimalizuje na krátkodobou predikovatelnost, ne na rychlost vývoje. Možná má na vás Scrum moc schůzí, tak zkusíte Kanban. Nebo spíše to co si myslíte, že je Kanban, ale Kanban to není, jen hromada úkolů a k tomu udělaný board v Jiře s několika sloupečky. Výsledky jsou každopádně v obou případech stejné.
Některé firmy se potom raději vrátí zpátky k projektovému stylu řízení, protože to jim aspoň poskytne určitou iluzi dlouhodobější predikovatelnosti. Rozhodně vám takový způsob může slíbit víc, než je agile schopen doručit.
Vstupuje Kingman
Až příliš pozdě ve své kariéře jsem narazil na Kingmanův vzorec. Tento vzorec se poprvé objevil v roce 1960 ve vědeckém článku J. F. C. Kingmana nazvaném “Fronta pro jednoho obsluhujícího při vysokém provozu” ("The single server queue in heavy traffic").
Vzorec vypadá nějak takto:
kde τ je střední doba obsluhy (tedy \( μ=\frac{{1}}{{τ}} \) je frekvence obsluhy), λ je střední doba příchodu, \( ρ=\frac{{λ}}{{μ}} \) je utilizace, ca je koeficient variability příchodů (tedy standardní odchylka času příchodu dělená střední dobou příchodu) a cs je koeficient variability doby obsluhy.
Rozumíte? Ne? Tak jo, já tomu taky ze začátku nerozuměl, pokusím se to vysvětlit. Tento vzorec ukazuje závislost délky fronty (jinými slovy kolik skutečně času uběhne mezi tím, než někdo zadá úkol a tím, kdy je hotový) na následujících proměnných:
- variabilita ve velikosti úkolů (jsou úkoly přibližně stejně velké nebo některé malé a některé obrovské?
- variabilita v době zadání (zadávají se úkoly průběžně nebo chvíli nepřijde nic a pak se jich nahrne spousta? )
- utilizace (poměr času práce a času nečinnosti toho, kdo úkol zpracovává, lidově řečeno kolik času se fakt maká)
Nemusíte vzorci rozumět detailně, abyste si z toho něco neodnesli. Důležité poučení je, že všechny tři výše uvedené proměnné zvyšují délku fronty, ale děje se tak zajímavým způsobem ve vztahu k utilizaci. Pod 85% utilizací obě variability hrají určitou roli, ale ne příliš významnou. I při vysoké variabilitě se práce odbavuje plynule. Jenže nad hranicí 85% procent začíná délka fronty explozivně růst exponenciálním tempem. Rázem se stává velmi citlivou na změnu v jedné nebo druhé variabilitě. Nad 95% utilizace se potom začíná limitně blížit nekonečnu. Minimálně to tak vnímají vaši uživatelé. No, jen se jich běžte zeptat.
Protože efekt vysoké utilizace je tak významný, mnohem větší než vliv obou variabilit, můžeme si vzorec ještě zjednodušit a přibližně ho vyjádřit jako
Pokud si tuto křivku vyneseme do grafu, vypadá to takto. Graf je převzat ze skvělé knížky DevOps Handbook. Všimněte si, jak nad 85% utilizaci doba čekání začne strmě růst.
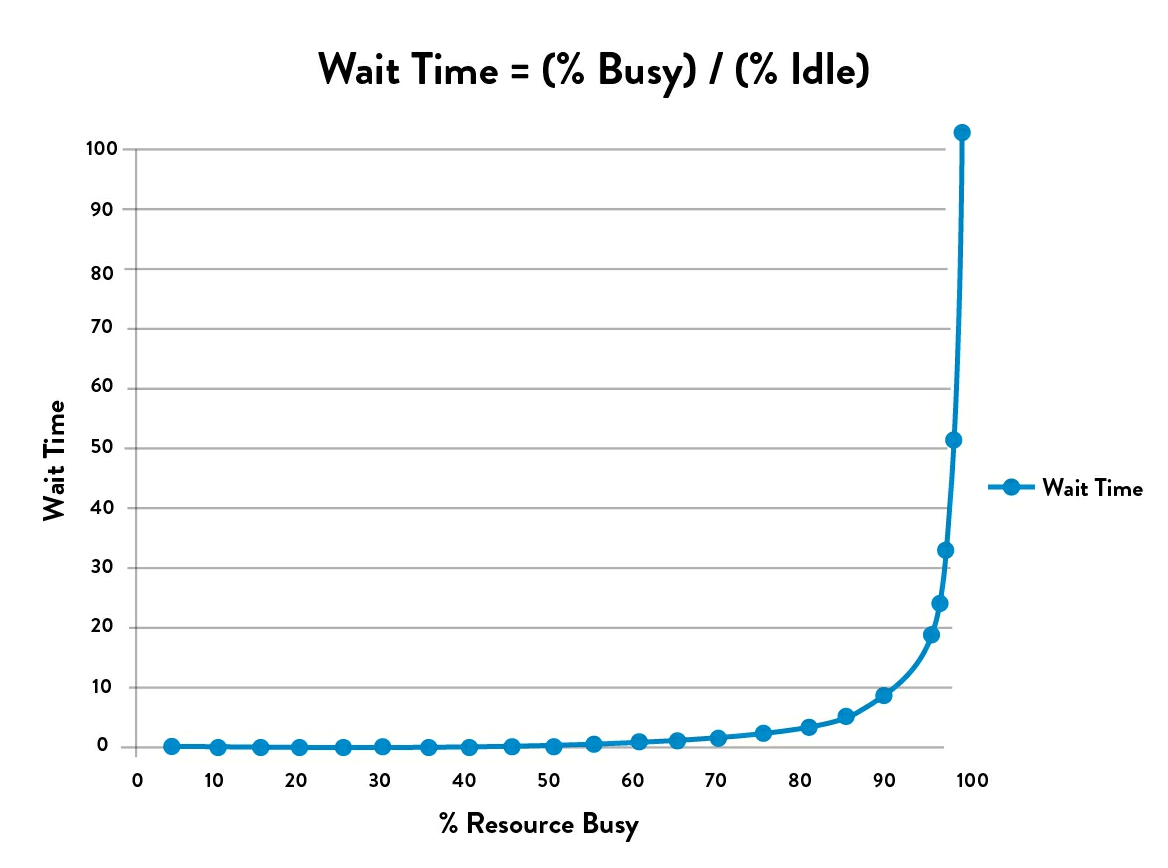
Dobře, a co se s tím dá dělat?
Variabilita v době příchodu
Variabilita v tom, kdy jsou úkoly zadávány se těžko ovlivňuje, protože často to je mimo vaši kontrolu. Ale i tak se dá něco dělat. Zvenku vypadá IT jako černá skříňka, do které se z jedné strany strká zadání a z druhé strany (občas) vypadne nějaká feature. Vlastní proces vývoje je ale samozřejmě složitější a často zahrnuje několik oddělených týmů, mezi kterými je potřeba předávat práci a i uvnitř IT existují fronty. Pokuste se omezit předávání úkolů v nějakých dávkách. A zkuste omezit ty předávky integrací více rolí do jednoho týmu. Nebo některé kroky úplně odstraňte. Opravdu potřebujete všechny ty sloupečky “čeká na schválení”?
Také se zkuste vyhnout takovým těm plánovacím sezením, kdy vaše představenstvo odjede na víkend do horského hotelu aby vytvořili seznam prioritních projektů pro příští kvartál. To tomu taky moc nepomáhá.
Variabilita ve velikosti úkolů
Velikost úkolů je něco, co můžeme ovlivnit výrazně více. Pokud si z agilního řízení vezmete jednu věc, měl by to být koncept User stories (Uživatelských příběhů?) Pokud je udělaná dobře, user story by měla poskytovat nějakou hodnotu pro uživatele a zároveň být dokončená v rámci jednoho sprintu. To znamená, že musí být dostatečně malá a tím přispívá k určité uniformitě ve velikosti, čímž snižuje variabilitu.
Jak velký projekt dobře nařezat na User stories by vydalo na samostatný článek (nebo možná knihu), ale zkusím vás aspoň navést pomocí jednoho nápadu: Raději vyřešte úplně problém jednoho uživatele nebo malé skupiny, než abyste částečně vyřešili problém všech uživatelů.
Utilizace
Nejvýznamnější, ale vlastně nejjednodušší na ovlivnění je utilizace realizačního týmu. Prostě plánujte méně práce a nechte vašim lidem víc volného pracovního času. Jednoduché ale neznamená snadné. Ta věc je hrozně neintuitivní. “Jak jako plánovat méně práce? Jak nám to asi tak má pomoc zrychlit?” Protože věda!
Pokud věda a překrásné matematické vzorce nestačí, můžeme sáhnout po jednom příkladu, který pochopí každý. To srovnání není dokonalé, ale funguje. Mluvím o dopravních zácpách na dálnici nebo městském okruhu. Předpokládám, že už jste v pár byli. Všimli jste si, že jakmile se začne provoz zahušťovat, trochu vás to zpomalí, ale ne zas tak moc? A najednou to dosáhne zdánlivě nelogického bodu, kde se nečekaně doprava úplně zastaví a posouvá se po centimetrech, i když to nemá žádný zjevný důvod jako třeba nehoda nebo práce na silnici?
Určitě jste slyšeli nějakého dopravního experta, jak říká, že pro předcházení zácpám v hustém provozu je potřeba jednak zpomalit a také nepřejíždět zbytečně z pruhu do pruhu. Tak to je kvůli tomu, že v hustém provozu má silnice vysokou utilizaci (prostě jsou menší mezery mezi auty). Přejížděním mezi pruhy se zvyšuje variabilita příchodu (každý segment každého pruhu je ve skutečnosti samostatnou frontou). Když jedete rychle, obtížně se vám podaří udržet konstantní rychlost vůči ostatním autům, pořád musíte přidávat a brzdit. Tím zvyšujete variabilitu v době trvání úkolu. Úkolem je v tomto případě “ujet pár metrů”. A protože se nacházíme v oblasti vysoké utilizace, i malá změna v jedné nebo druhé variabilitě má obrovský efekt na velikost fronty. A vznikne dopravní zácpa.
Dává to smysl? Podělte se dole v komentářích.
TL;DR
Je potřeba zpomalit abyste mohli jet rychle. Až tak jednoduché to může být. Snažte se udržet utilizaci týmu pod 85%. Stejně tak jako servery nevytěžujeme na 100%, neměli bychom se snažit vytížit naše týmy na 100%. Pokud to tak děláme, bude se délka fronty blížit k ∞.
Comments