You said the feature will take one day of development, but it has been three months and it is still not finished!
Our marketing created the campaign page themselves, because it takes IT forever to setup anything!
Sounds familiar? I have been on both ends of these conversations, but mostly on the “being yelled at” end. For a long time, I was puzzled. Why was this happening?
Setting the stage
You have a reasonable development team. Certainly expensive enough for your CFO to give you hard time. Despite that, things are still moving at snail’s pace, at least according to your business users. Stuff is coming out of your pipeline, sure, but many good ideas, which could even be quickly developed, are killed, because no-one wants to wait until next quarter to test a simple business hypothesis.
Many organizations adapt agile development methodologies with high hopes of solving this very issue. Often that fails miserably. What those Scrum certified consultants fail to mention is that Scrum optimizes for short term predictability, rather than throughput. Maybe Scrum has too many meetings for you, so you pick Kanban. Or rather what you think is Kanban, though it probably is not Kanban, but a single pile of tasks and a Jira board with few columns to go along with it. Result is more or less the same in both cases.
Few companies even choose to go back to waterfall project management, because that at least gives them the illusion of long term predictability. It can definitely promise more than agile can deliver.
Enter the Kingman
Too late in my career have I discovered Kingman’s formula. The formula originally appeared in an ancient math paper by J. F. C. Kingman in 1960 named “The single server queue in heavy traffic”. (Mind you, the server mentioned here is an actual person serving someone)
The formula goes something like this:
where τ is the mean service time (i.e. \( μ=\frac{{1}}{{τ}} \) is the service rate), λ is the mean arrival rate, \( ρ=\frac{{λ}}{{μ}} \) is the utilization, ca is the coefficient of variation for arrivals (that is the standard deviation of arrival times divided by the mean arrival time) and cs is the coefficient of variation for service times.
Understood? No? OK. I did not get it either at first, so let me explain. This formula, from the field of queueing theory, puts into relation the queue length (or in other words, how long does it actually take in real world days to develop anything here) with the following variables:
- variability in task size (are the tasks similar in size or some are small and some really big?)
- variability in task arrival rate (are the tasks coming in steadily or in batches/peaks?)
- utilization (what is the ratio between the entity performing the task is idle versus busy)
You don’t need to understand it completely in order to learn from it. The important takeaways are, that all three of the above increase the queue length. But they do so in a peculiar way with regards to the utilization. Under about 85% utilization, the variability does play a role, but not that big. Even with high variability, the work flows smoothly. But above 85% utilization the graph of queue length seems to explode exponentially. It becomes extremely sensitive to the two variabilities and above 95% the queue length starts quickly approaching infinity. Or it definitely feels that way to your users. Just ask them.
Because the effect of high utilization is so large, much bigger than the influence of the two variabilities, the formula can be simplified and approximated as
If you plot it in a graph, it looks something like this. The graph is borrowed from The DevOps Handbook. Just notice how the wait time really takes off after hitting 85% utilization.
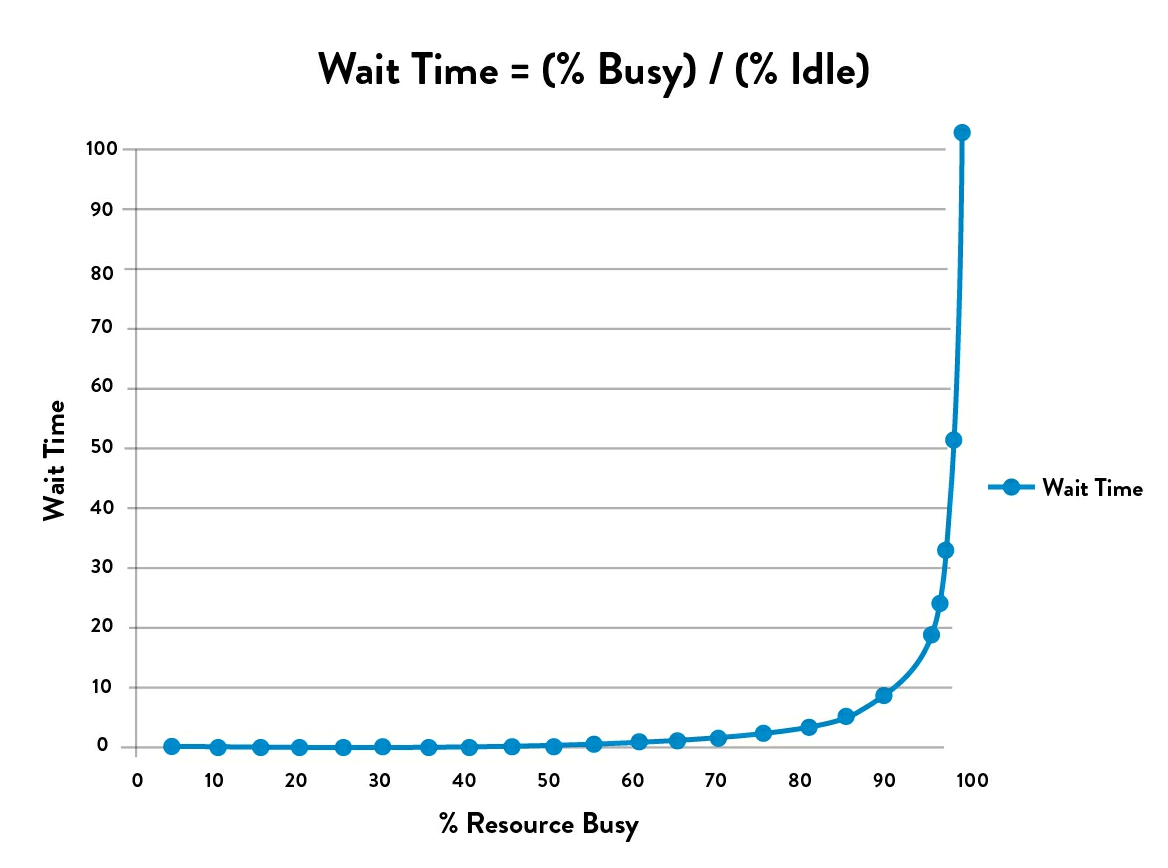
Now, what can we do about it?
Variability of arrival rate
The variability of arrival rate is difficult to influence, as the tasks often originate outside of your control. There are still things you can do. To the outside world, IT looks like a opaque box, where you insert the tasks on one end and (sometimes) features come out the other end. The actual process however often involves multiple teams where the work is handed over and mini-queues also exist. Try to avoid batching of tasks in these internal handovers for more smooth workflow. And try to reduce the number of handovers by integrating more roles into a single team or eliminate the stages ruthlessly. Do you really need all those approval columns?
Also, try to avoid big management planning sessions, where the board locks itself in a mountain resort for the weekend and creates a list of high priority projects for the following quarter. That does not help.
Variability of task size
Task size is something we can influence more directly. If you take one thing from agile, it’s the concept of User stories. If done right, a single user story should provide some value to some users and be ready to deploy within the two-week sprint. That means it should be small enough and uniform enough to help reduce the variability.
Slicing user stories is an art in itself and would probably do for a separate article, but I will leave you with just one idea, that should help: Try to solve a problem completely for a single class of users, however small that class is, rather than partially solve a problem for everyone.
Utilization
The most important, but actually probably the simplest to influence, is the utilization of the team. Just plan less work and give your team some slack. But simple does not mean easy. It’s very counterintuitive. “What do you mean, plan less work? How is that going to speed things up?” Well, because science says so!
But if science and beautiful math formulas fail to convince, you can reach for an example everyone should be able to understand. The analogy is not perfect, but works pretty well. I am talking of course about traffic jams on the highway. I assume you have been in few. Have you noticed, how when the number of cars on the highway starts to increase, the speed you are driving goes down a bit? And then, it reaches some kind of seemingly illogical point, where suddenly everything comes to a screeching halt, even when there is no apparent reason like an accident or closure?
Remember how the traffic experts keep telling you: “If there is a lot of traffic, slow down and avoid switching lanes to avoid causing a traffic jam?” Well, that’s because with a lot of traffic, the road has a high utilization (ie. less space between cars). By switching lanes you are increasing the variability of arrival (each segment of each lane works actually as a separate queue). By going fast, you are unable to keep driving a same constant speed like everyone else and thus increase the variability of the duration of the task. You are constantly speeding up and slowing down. The task in this case means “moving one meter forward”. Under high utilization, even slight increase in either of the two variabilities or the utilization itself has a huge effect on the queue size. The result: traffic jam.
Makes sense? Let me know in the comments below.
TL;DR
You have to slow down to go faster. It’s as simple as that. Aim for below 85% utilization. Same as we do not run our servers at 100% utilization, we should not run our teams at 100% utilization. If you do, expect your queues to approach ∞.
Comments